
Ultimate solution to 51% attacks: amend the Nakamoto consensus
Article by Dexaran posted on Github and Bitcointalk during August, 2020.
TL;DR:
The Nakamoto consensus is a set of rules that is intended to define a trustless peer-to-peer electronical cash system that can solve a double-spending problem without financial institutions involvement. It fails to do so in some circumstances.
The main flaw of the Nakamoto consensus is that it assumes the possibility to rewrite the history of transactions in the past up to a potentially unlimited point of time, while in reality not all off-chain events can be reversed up to any point of time. The flaw is expressed in "The longest chain is always the right chain" paradigm which is the root of all 'stealth mining' attacks. The new paradigm "The longest chain is the right chain IF it does not suggests to reorganize more than X blocks of the already existing chain" must be applied in order to make these attacks impossible.
Another flaw of Nakamoto consensus is that it assumes that a node can trust itself. In reality only a group of geographically spreaded nodes can trust that the whole group is on the correct chain if these nodes are at the same chain and these nodes trust each other i.e. they belong to a single owner.
Here (X + 1) is the safe number of block confirmations, after which no 51% attacks are possible.
A new paradigm "The longest chain is the right chain IF it does not suggests to reorganize more than
Xblocks of the already existing chain" must replace the old "The longest chain is always the right chain" paradigm.A new paradigm "An isolated node can not trust itself" must be applied.
Definition of the problem
A purely peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution. Digital signatures provide part of the solution, but the main benefits are lost if a trusted third party is still required to prevent double-spending. We propose a solution to the double-spending problem using a peer-to-peer network. - The first lines of the Bitcoin whitepaper
As we can see in the Bitcoin white paper quote above the main goal of the Nakamoto consensus is to define a set of rules that would help to build a trustless peer-to-peer electronical cash system that can solve a double-spending problem without financial institutions involvement.
It's important to note that the purpose of Bitcoin (and cryptocurrencies) is not to define the "chain" as the ultimate truth but to design a payment method that would allow for exchange of crypto currencies with off-chain goods.
Example: Party A purchases a car from party B with such an e-cash system. Party A then drives a car away and realizes that the paid cryptocurrency units are back to the balance of party A a couple hours after the deal is completed. Party B gets nothing for the sold car as the result. Such an e-cash system is not solving the double-spending problem - the described example can be a result of a so-called 'stealth mining attack'.
Pure Nakamoto consensus implementation is naturally prone to 'stealth mining' or '51% attacks' due to the fact that it relies on a mistaken assumption and does not take into account the real environment conditions. These flaws of the Nakamoto consensus could be fixed thus making 51% attacks on POW chains impossible.
It should be noted that this is not the first flaw of the original Bitcoin idea and implementation. A number of already fixed vulnerabilities can be found here. For more information you can review this article describing another 9 issues that have been fixed since the launch of Bitcoin. The process of identifying and fixing flaws is a natural part of a life cycle of an idea or software.
Theory behind 'stealth mining' attacks
The goal of a stealth mining attack is to allow a certain transaction to happen on the chain, and then overwrite a number of blocks up to the block in which the transaction occurred, thus making the transaction non-existent and preventing the transfer of value at the same time if the transaction has already been cashed out, thus allowing the double spending of the of the described transaction.
Step by step:
There is a malicious miner at the network. At block Y the malicious miner disconnects from the main network and starts mining his own branch of the chain. The miner does not broadcast his blocks to the network. Main network nodes know nothing about the existence of an alternative chain branch.
At some point of time the malicious miner performs a transfer of 10,000 tokens at the main network. Let's assume that the transaction is included in block (Y+100) at this example.
The malicious miner keeps mining his own chain privately. He is free to include or not to include any transactions into blocks of his privately mined chain. The malicious miner does not include his transaction into any block of his chain (while the transaction happened on the main chain at block Y+100).
Once the transaction is confirmed the malicious miner is cashing it out. For example he can buy himself a pizza at a moment of time while the highest block of the main network is (Y+201).
The goal of the malicious miner is to develop a longer chain (typically by having more hashing powers than the main network has). In this example we can assume that at some point of time a malicious miner has mined 230 blocks since the moment he disconnected from the main network at block Y. At the same time the main network has only 225 new blocks since the block Y. The highest block of the main network is now (Y+225) while the highest block of the privately mined chain is (Y+230).
The malicious miner now restores connection between his node and the main network peers. Malicious miner's node starts broadcasting its chain to the main network. The highest block of the main network is (Y+255) which is less than (Y+230)which means that all the main network nodes are starting to reorganize their chains thus syncing into the longest chain of the malicious miner.
The block (Y+100) of the network is overwritten by (Y+100) block of the malicious miner's chain which does not include a transfer of his 10,000 tokens. It looks like this transaction has never happened and never existed which means that these 10,000 tokens are still at the malicious miner's balance. He can spend them again i.e. buy himself the second pizza with the same 10,000 tokens. This is how double-spending happens.
Essentially the malicious miner can cancel any transfers that happened between the block Y and block (Y+225) of the main network by not including them into blocks of his privately mined chain. The worst thing is that he is not obligated to broadcast anything to the main network in order to make his chain legit thus he can make it last for as long as he wants while the remaining participants of the main network are in a complete uncertainty about the fact that an alternative chain branch exists somewhere.
Nakamoto consensus observations
1. The ability to reorganize a chain in the past is redundant
Nakamoto consensus assumes that the longest chain is always the right chain. As a result, even if some chain is pretty much different from the chain a node is currently at, then the node will resync with the longest chain and throw away all the blocks from the previous chain. This may cause a reorganization of all the transactions for a prolonged period and effectively rollback hours, days or even weeks of financial activity in theory. This is evident that this is not how a trustless electronic cash system should work. It is known that cash does not work like this.
It's fair to question why such a mechanic is needed at all, and what are the scenarios that require reorganizing a huge number of blocks?
The answer is that in a normal state of the network such a reorganization must never happen.
In reality if such a reorganization would happen naturally then it would be a disaster for the network already. Billions of dollars could be double spent on occasion in such case. Even the reorganization of a number of blocks, which slightly exceeds the number of confirmations of exchange deposits (100 confirmations for Ethereum on some exchanges), would be a disaster for the network.
These reorganizations never happen naturally, as POW chains remain in a more-or-less-consensus state most of the time, which means that it is possible that some nodes are slightly behind or slightly ahead of the rest of the network. The purpose of the consensus rules is to resolve small conflicts between nodes in case some miners can find different valid blocks at nearly the same time which causes a minor disruption in the consensus state.
There is no such an event that could result in a necessity to resync a huge number of blocks in the past which means that the ability to do so is redundant and even malicious on its own.
2. Every node that proposes to reorganize a huge number of blocks in the past is malicious
It may happen that a node is on the longer chain that suggests to rewrite a huge time frame of transaction history if:
The node was disconnected from the network and mined privately for a prolonged period of time. In this case the node is malicious as it has intentionally splitted out with the only goal to cancel some transactions of the main network.
The node controls overwhelming superiority of the hash power of the network and it has mined a number of blocks in a row while the rest of the nodes failed to sync with it at a time. This is unlikely to happen because all the participants will attempt to sync with the owner of the superior hashpowers as soon as it will be at least one block ahead of the rest of the network. However the reorganization of blocks in the past must be allowed up to a certain depth in order to make it possible for nodes to follow the owner of the superior hashpowers.
The node refused to sync with the longest chain and kept mining its own chain until it turned out that the chain is the longest. In this case the node must be considered malicious as it refused to sync with the longest chain earlier. This can only happen in some edge cases if the node owner controls somewhat about 50% of the hash power of the network.
3. The network does not consist of continuously connecting and disconnecting nodes
Consensus on the entire state of the blockchain and validity of all of its transactions is distributed to thousands of nodes across the world that continually connect and disconnect from the network.
This assumption of the Nakamoto consensus is mistaken. First of all there are nodes that are constantly operational - bootnodes, blockchain explorer nodes, exchange nodes, nodes of mining pools, wallet nodes, other RPC nodes. In case of bootnodes if these will go down then the network is on the edge of a collapse already as new participants will not be able to join and some artificial updates and establishment of new bootnodes would be necessary.
Now what is "the network"? - A network is a collection of nodes that are in a state of consensus and are currently online. With that being said, a set of universal consensus rules that would help to achieve consensus from scratch at any time can be replaced with a set of rules that will help to achieve consensus for the first time and then maintain the achieved consensus between online nodes.
Once the consensus is achieved for the first time and the network already exists only the maintaining rules must be applied.
4. "Entity" is not equal to "single node"
Nakamoto consensus assumed that:
network participants will rely on roughly equal CPU powers to generate new blocks
network participants will rely on their own nodes to send transactions
network participant is a node
All three assumptions actually turned out to be wrong. CPUs are no longer used as a source of hashpower to generate blocks in most cryptocurrencies - GPUs (in Ethereum) or even ASICs (in Bitcoin) are used instead.
In newer blockchains keeping a fully synced node in order to send a transaction is no longer viable. RPC nodes are used instead.Once a transaction was signed it is sent to the RPC node. The RPC node has two options (1) to broadcast the signed transaction to the network, and (2) not to broadcast the signed transaction to the network. As the RPC node can not modify the transaction or retreive the private key that was used to sign it then it is reliable to use a special service that provides an RPC node instead of constantly syncing a full node for each transaction.
As the result there is absolutely no reason for a user of the network to keep a full node. At the same time there is no reason to assume that one entity controls just one node.
In reality, the network participants were divided into two levels - network users and network 'gateways' or service providers. These service providers (pools, exchanges, wallets, explorers) keep their nodes synced and these are constantly remaining in a consensus state with each other. Any discrepancy between these service providers is an abnormal situation for the network.
As a result, service providers are already relying on multiple nodes to mitigate synchronization latency due to the geographic distance of nodes from each other. Some blockchain explorers as etherscan rely on their "background" nodes to confirm transactions, most exchanges have multiple nodes as well. Mining pools are also incentivized to have multiple geographically spread nodes to keep their customers mining the correct chain that will not be orphaned due to the latency of pool's node.
The solution: amendment to Nakamoto consensus
As long as a majority of CPU power is controlled by nodes that are not cooperating to attack the network, they'll generate the longest chain and outpace attackers. - Bitcoin whitepaper
The original Nakamoto consensus is not designed for systems where more than 51% of hashpower is controlled by a malicious entity. However it is possible to apply a modification that would mitigate the most common attacks otherwise possible on a pure Nakamoto consensus. In this case we assume that even a single entity controls more than 51% of hashpower of the network then it can not harm the already-existing already-established network. Once the network achieved the consensus, it will no longer be vulnerable to 51% attacks - in this case, the attacker can only follow the consensus of the existing network without any possibility of intentionally causing it to disagree with events that have already happened outside the network.
Based on the fact that the ability to reorganize any number of blocks in the past is the root of 51% attacks and the most dangerous flaw in the Nakamoto consensus, there is a good reason to exclude this ability from the consensus rules.
New paradigm must look as follows:
The longest chain is the right chain as long as it does not suggest to reorganize more than X blocks in the past. If a peer offers a longer chain that proposes to reorganize more than X blocks of the chain that a node is currently in, then that chain should be rejected and the node should remain in the current version of the chain.
This makes stealth mining attacks non-profitable as a malicious entity controlling 51% of hashing powers can not create a large private chain and then replace the existing chain with it as nodes of the already-existing already-synced network will refuse to accept the new history of transaction if it is overwriting more than X existing blocks while at the same time the attacker can not harm any entity of the network if the entity relies on (X+1) network confirmations prior to commiting any actions. If 51%-attacker has generated a significantly larger chain offspring and failed to broadcast it to the network at a time but kept mining it then the network will refuse to sync with this chain offspring and the 51%-attacker will lose his rewards for the mined blocks.
It should be noted that if any entity controls 51% or more of the hash powers of the network, but it does broadcast its new blocks to the network after they have been mined, then that entity can still participate in the network as it did before the amendment. Here X should be a reasonably small number of blocks that corresponds to the amount of time that exchanges typically require for the deposit to be confirmed. All the exchanges must then set the number of required network confirmations greater than X as it is not possible that something that happened longer than X blocks ago would be reverted. The new paradigm turns the ability of 51%-attacker to harm the network into the ability of 51%-attacker to harm himself only.
Edge case attack
In some circumstances it may happen than a malicious miner is privately developing a chain with an intention to destroy the state of consensus among nodes of the main network. In this edge case attack assume that the number of block reorganizations X = 100, which means that the blockchain could not be reorganized more than 100 blocks in the past.
Assume that the majority of "loyal" nodes is developing
chain_Awhile the attacker is trying to developchain_BAttacker is starting to develop his own
chain_Bat blockYThe
chain_Areaches blockY+100Some miner at
chain_Ahas found a blockY+101and broadcasted it to the network. At the same time the attacker has found a block with the heightY+101at thechain_B. The attacker is broadcasting his block to the network at the same time.The network is not yet synced and some nodes have not yet reached the block
Y+101of thechain_Aand thus, these nodes would sync with thechain_B'sblockY+101thus rewriting 100 blocks of thechain_Awhich is still allowed by new consensus rules.Those nodes which synced the block
Y+101of thechain_Awould refuse to sync with thechain_Bbecause this would require them to overwrite more than 100 blocks.The chain is splitted as some nodes has followed
chain_Band some nodes remained atchain_A. These nodes would never sync again as block heights will only grow increasing the number of blocks that must be overwritten since the block Y in order to sync these chains.
It should be noted that this edge case attack is not profitable for the creator of chain_B as he can not perform any double-spends. However the creator of chain_B may attempt to perform replay attacks on the opposing chain in case some targeted parties such as exchanges has followed the chain_A while the rest of targeted parties followed the chain_B.
It is worth to mention that predicting which party follows which chain and causing an ideal split between the networks is not a deterministic task. Edge cases are tied to the natural imperfection of POW systems and latency of node syncing.
Addressing the edge case attack
In programming, an edge case typically involves input values that require special handling in an algorithm behind a computer program. -- Edge case handling in software engineering
Internal resolution within the multi node entity
Having multiple geographically distant nodes can solve the problem for an entity. While a single node can not solve the problem on its own as it can not determine whether a chain is correct or not in advance the entity consisting of multiple nodes definitely can do so.
The root of the edge case problem is that geographically distanced nodes consider different blocks of the same height at the same time and then its too late to reorganize the chain. In fact two blocks with the same height are not equal and it is possible to determine which block is more 'valid' than the other by certain criteria (timestamp, hashes, difficulty or other variable).
If all the nodes of the network would simultaneously receive both blocks at the same time without any delay then the problem of edge case would not exist as the nodes would easily determine which of the blocks needs to be accepted.
In case of a multi node entity, if one node went through the reorganization of its chain at close-to-edge-case depth then it must flag it for the rest of the nodes. In case some nodes within the group are at different branches of the chain starting from block Y then the nodes must resolve the conflict within the group by whitelisting the best of (Y+X)th blocks of these two branches.
The entity must halt its operations as soon as at least one node is flagging the close-to-edge-case reorganization.
Synchronization prevention attack
It is not certain if there are parallel universes or not, but if you want to buy my cell phone, you want to be in the universe where this phone exists. If you then want to call your friend, you want to stay in the universe where the network provider and your friend exist.
It is possible that an attacker will split off the main network at some block Y and then he will develop a longer offspring of the network. The attacker can maintain this chain for potentially unlimited time frame as long as he is controlling more hashing powers than the main branch of the network. After main network branch contains at least (Y+X) blocks it is no longer possible that this branch will reorganize into attackers branch.
In this case the attacker may prevent new nodes from syncing with the main network that will remain its consensus by excluding the attacker. As long as the attacker maintains his branch and it is longer than the main network branch the new node would sync into the attackers branch by default following the "the longest chain is the right chain" paradigm.
In this case there would be two networks with stable consensus - the main network and the attackers branch. The newcomer's node should explicitly whitelist the desired branch to sync with in this case.
This attack is costly and the attacker must continuously spend his funds/power on maintaining the alternative branch without any real opportunity to benefit from it aside of causing problems for newcomer's syncing nodes. At the same time he could benefit by contributing to the main network and thus earning the rewards that could be used on the main network.
Eclipse Attack
Eclipse attack step-by-step
Eclipse Attack enables a would-be bad actor to isolate and subsequently prevent their target from attaining a true picture of real network activity and the current ledger state.
This attack is made possible because a decentralized network does not let all nodes simultaneously connect to all other nodes on the network. Instead, for efficiency, a node connects to a select group of other nodes, who in turn are connected to a select group of their own. For example, a Bitcoin node has eight outgoing connections; Ethereum 13.
The goal of the eclipse attack is to isolate a node or a group of nodes and then force an isolated node to split off from the main network because the node does not know that the "main network" exists at that moment.

Here is an illustration of the network. We assume that the green node will be targeted by the attacker. Black nodes are random nodes of the network that remain in a consensus state. Red nodes are malicious nodes.
Step 1: The attacker is launching his own nodes
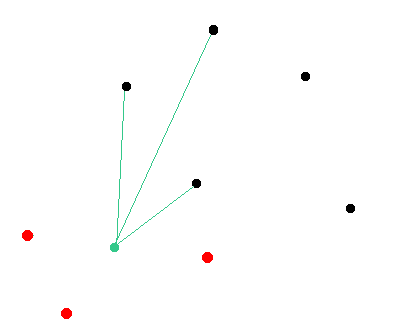
It is worth to mention that the attacker must be sure that his malicious nodes are connected with the targeted nodes and there are no external peers that could suggest their own version of the chain to the targeted node.
The targeted node is always trying to follow the consensus rules. As the result if the attacker will create a longer chain at some point of time and let targeted node sync it then the targeted node will broadcast the attackers chain to the network and the rest of the mainnet nodes would sync it thus the attack will not be possible in this case because the nodes will not split off and all of them (including pools and hashrate sources) will just adop the attackers chain.
The goal of the attacker is to develop a chain and broadcast it to the targeted node so that this targeted node would adopt the chain but not to broadcast it to the rest of the mainnet nodes so that they adopt this chain at the same time.
If the attackers nodes would attempt to broadcast their version of the chain to the targeted node but the targeted node will still have connections to the nodes of the main network then the targeted node will follow the consensus of the main network and the attack will fail.

A node may only follow attackers chain IF (1) the attackers chain does not violate any consensus rules written in the code and (2) there is no other chain that is better than the attackers chain. Otherwise the targeted node will refuse to follow the suggested attackers chain.

In order to perform a successful eclipse attack the attacker must develop a chain that does not violate any consensus rules (i.e. the attacker still need a decent share of the mainnet hashrate) and make sure that the targeted node does not have any connections to the mainnet nodes that would suggest the mainnet version of the chain against the attackers chain.
Step 2: The attacker is isolating the targeted node

Here we will not investigate the methods of isolating a node. It should be noted that this is not an easy task because the attacker can not just tell a node "Please, drop your current connections and connect to my nodes instead".
Here is more background on eclipse attacks:
Step 3: The attacker is creating his own chain and tricking the targeted node to follow it

In this example the attacker is starting to develop his own chain once it is certain that the targeted node does not have any connections with the mainnet nodes.
The attacker should not broadcast his version of the network to any mainnet nodes and drop any connections with the mainnet.

In this case the attacker is creating an isolated environment for the targeted node surrounded by malicious nodes interconnected with each other.

Step 4: Damaging the network
The attacker can perform his actions once the targeted node is isolated. In case the attackers goal is to perform any double spendings and the targeted node is an exchange node then the attacker should deposit his funds and make the trades.
In case the attackers goal is to disrupt the network then the attacker must maintain the network for more than X blocks. In this case the targeted node would never sync with the mainnet again even if it will receive the "mainnet version of the chain" from any mainnet node because it will cause a long reorganization of the targeted node's chain.
Have a connection to some whitelisted mainnet node.
It should be noted that a node can only be "trusted" if it belongs to the same owner. In reality exchanges and block explorers already have "background" nodes so they are not prone to this kind of attacks.

In this case a node has connection to some other node it will not follow the attackers chain.
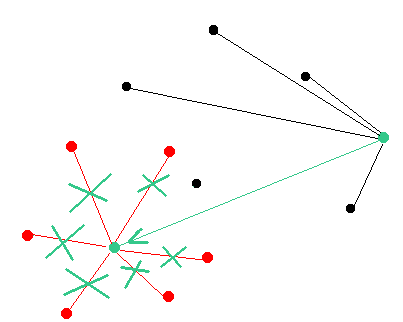
Even if there is a single node that can operate as a bridge between the targeted node and mainnet nodes - the attack will fail. There are two possible scenarios of the attack failure: (1) if the attacker has developed the longest chain then it will be adopted by the mainnet nodes and (2) if the attacker has developed a shorter chain then the targeted node will reject it and resync with the mainnet as soon as the attacker will attempt to suggest his version of the chain.
The attacker, however, may attempt to isolate the whitelisted node as well. This will tremendously increase the complexity of the attack.

This connection between the targeted node and the whitelisted node belonging to the owner of the targeted node may be private.

In this case the attacker does not know which node to target.

This effectively turns the attack into gambling as the attacker does not know whether he have any chance to succeed or not unless he has 100% control over the all nodes of the network.

These nodes may not be whitelisting each other at all.
In some cases these nodes do not even need to be interconnected with each other. The above example was the simplest solution but in reality this is not how background nodes operate.

Imagine there is an exchange. It does not tell anyone which nodes it owns. However, the exchange must compare the results of its nodes in order to credit someone's deposit. If there is a discrepancy between the nodes owned by the exchange, the deposit should be halted until further investigation.
No one knows which nodes of the network are inter-related to each other. It is better to have geographically distanced nodes and compare their results in order to address natural hardware imperfection issues such as network latency.
Exchanges and other responsible network entities may also have 3, 5 or 10 nodes to secure their funds. This increase in complexity is a reasonable measure to eliminate multi-million dollar losses from 51% attacks.
The "Node cannot trust itself" paradigm as a solution to eclipse attacks
The described attack and the described countermeasures are only related to the imperfection of the hardware and network latency. This attacks are not related to the underlying consensus. As the result - it is definitely known which chain was correct at which moment of time. While a single node can not rollback the time and objectively decide whether a split was legit or not - it is definitely possible to do so for the owner of this node if he has another node to compare with.
There is a set of rules that would help the mainnet nodes to stay synced and resist the attack:
Don't trust a single node - it can be isolated or suffer edge case issues.
Have multiple nodes. Compare their state with each other.
Don't tell anyone which nodes are yours and how much "background" nodes you have.
It is always possible to determine which chain is correct but your node may not be on a correct chain for some reason (most likely technical problems or network latency).
Help your lagging node to sync to the correct chain using those nodes that are on the correct chain.
Copyright
This document is licensed under GNU Free Documentation License v1.3.
Last updated